

This is a nice problem, but there is little clear information on the Web about how to accurately scale a web application from zero to hundreds of thousands of users. Usually, there are either fire solutions or the elimination of bottlenecks (and often both). Therefore, people use fairly stereotyped tricks to scale their amateur project into something really serious.
Let’s try to filter out the information and write down the main formula. We are going to step by step scale an imaginary photo-sharing site from 1 to 100,000 users.
We will write down what specific actions need to be done when increasing the audience to 10, 100, 1000, 10 000 and 100 000 people.
1 user: 1 machine
Almost every application, whether it’s a website or a mobile application, has three key components:
- API
- database
- client (mobile application or the website itself)
The database stores persistent data. The API serves requests for and around this data. The client transfers the data to the user.
We came to the conclusion that it is much easier to talk about scaling an application if, from the point of view of architecture, client entities and APIs are completely separated.
When we first start creating an application, all three components can be run on the same server. In a way, this reminds us of our development environment: one engineer runs the database, API, and client on the same computer.
Theoretically, we could deploy it in the cloud on one instance of DigitalOcean Droplet or AWS EC2, as shown below:
 With that said, if the site has more than one user, it almost always makes sense to highlight the database level.
With that said, if the site has more than one user, it almost always makes sense to highlight the database level.
10 users: taking the database to a separate level
Dividing a database into managed services such as Amazon RDS or the Digital Ocean Managed Database will serve us well for a long time. It’s a bit more expensive than self-hosting on a single machine or an EC2 instance, but with these services out of the box you get many useful extensions that will come in handy in the future: multi-region backups, read replicas, automatic backups, and much more.
This is how the system now looks:

100 users: taking the client to a separate level
Fortunately, our application really liked the first users. Traffic is becoming more stable, so it’s time to move the client to a separate level. It should be noted that entity separation is a key aspect of building a scalable application. Since one part of the system receives more traffic, we can separate it in such a way as to control the scaling of the service based on specific traffic patterns.
That’s why we like to represent the front-end separately from the API. This makes it very easy to talk about development for several platforms: web, mobile web, iOS, Android, desktop applications, third-party services, etc. All of them are just clients using the same API.
For example, now our users most often ask to release a mobile application. Separating client entities and APIs makes it easier.
Here’s what the system looks like:
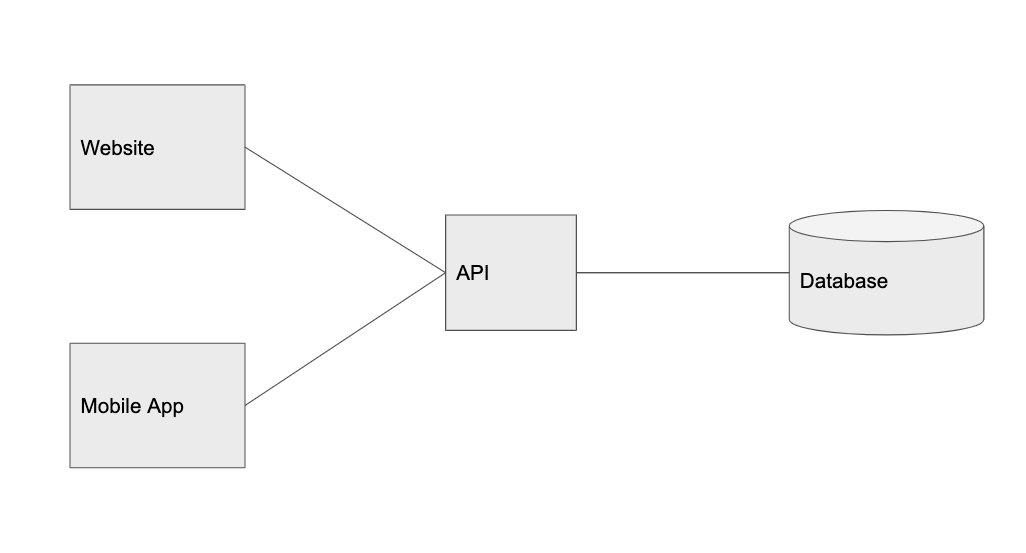
1000 users: add load balancer
Things are going well. Graminsta users are uploading more and more photos. The number of registrations is also growing. Our lone API server has difficulty managing all traffic. Need more iron!
The load balancer is a very powerful concept. The key idea is that we put the balancer in front of the API, and it distributes the traffic among individual service instances. This is the way of horizontal scaling, that is, we add more servers with the same code, increasing the number of requests that we can process.
We are going to place separate load balancers in front of the web client and in front of the API. This means that you can run multiple instances that execute the API code and the web client code. The load balancer will forward requests to the server that is less loaded.
Here we get another important advantage – redundancy. When one instance fails (possibly overloads or crashes), we still have others that still respond to incoming requests. If a single instance worked, then in the event of a failure the whole system would fall.
The load balancer also provides automatic scaling. We can configure it to increase the number of instances before the peak load, and reduce when all users sleep.
With a load balancer, the API level can be scaled to infinity, we just add new instances as the number of requests increases.

10,000 users: CDN
Perhaps it should have been done from the very beginning. Processing requests and accepting new photos begin to load our servers too much.
At this stage, you need to use a cloud service for storing static content – images, videos and much more (AWS S3 or Digital Ocean Spaces). In general, our API should avoid processing things like uploading images and uploading images to a server.
Another advantage of cloud hosting is its CDN (in AWS, this add-on is called Cloudfront, but many cloud storages offer it out of the box). CDN automatically caches our images in various data centers around the world.
Although our main data center can be located in Ohio, if someone requests an image from Japan, the cloud provider will make a copy and save it in their Japanese data center. The next person to request this image in Japan will receive it much faster. This is important when we work with large files, like photos or videos that take a long time to upload and transmit across the planet.
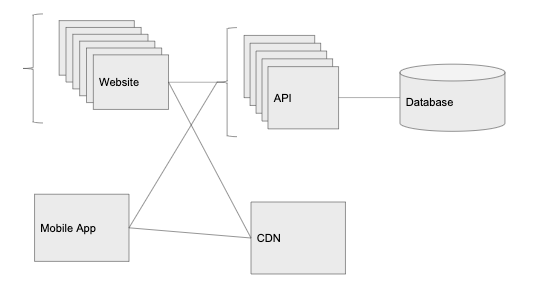
100,000 users: data level scaling
CDN really helped: traffic is growing at full speed. The famous video blogger, Maid Mobrick, has just registered with us and posted his story, as they say. Thanks to the load balancer, the level of CPU and memory usage on the API servers is kept low (ten API instances are running), but we are starting to get many timeouts for requests … where did these delays come from?
After a little digging in the metrics, we see that the CPU on the database server is 80-90% loaded. We are on the limit.
Scaling the data layer is probably the hardest part of the equation. API servers serve stateless requests, so we just add more API instances. But with most databases, this will not work. We will discuss the popular relational database management systems (PostgreSQL, MySQL, etc.).
Caching
One of the easiest ways to increase the performance of our database is to introduce a new component: the cache level. The most common caching method is to store key-value records in RAM, such as Redis or Memcached. Most clouds have a managed version of these services: Elasticache on AWS and Memorystore on Google Cloud.
The cache is useful when a service makes many repeated calls to the database to get the same information. In fact, we access the database only once, save the information in the cache – and do not touch it anymore.
For example, if someone goes to Graminsta service, every time someone goes to the Mobric star profile page, the API server requests information from his profile in the database. It happens over and over again. Since Mobrick’s profile information does not change with every request, it’s great for caching.
We will cache the results from the database in Redis using the user: id key with a validity period of 30 seconds. Now, when someone enters Mobrick’s profile, we first check Redis, and if the data is there, we simply transfer it directly from Redis. Now, queries to the most popular profile on the site practically do not load our database.
Another advantage of most caching services is that they are easier to scale than database servers. Redis has a built-in Redis Cluster cluster mode. Like load balancer1, it allows you to distribute the Redis cache across multiple machines (across thousands of servers, if necessary).
Almost all large-scale applications use caching; this is an absolutely integral part of the fast API. Faster request processing and more productive code – all this is important, but without a cache, it is almost impossible to scale the service to millions of users.
Reading replicas
When the number of database queries has increased dramatically, we can do one more thing – add read replicas in the database management system. Using the managed services described above, this can be done in one click. The read replica will remain relevant in the main database and is available to SELECT statements.
Here is our system now:
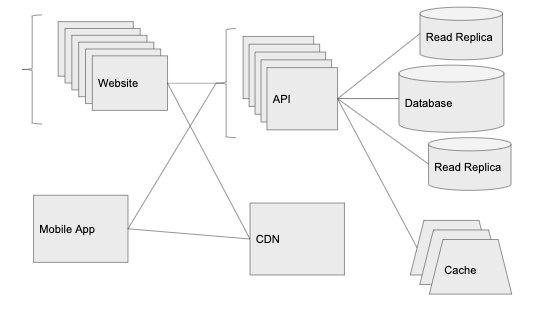
Further actions
As the application continues to scale, we will continue to separate services to scale them independently. For example, if we start using Websockets, it makes sense to pull the Websockets processing code into a separate service. We can place it on new instances behind our own load balancer, which can scale up and down depending on the open Websockets connections and regardless of the number of HTTP requests.
We also continue to fight against restrictions at the database level. It is at this stage that the time has come to study the partitioning and sharding of the databases. Both approaches require additional overhead, but they allow you to scale the database almost to infinity.
We also want to install a monitoring and analytics service like New Relic or Datadog. This will help identify slow queries and understand where improvement is needed. As we scale, we want to focus on finding bottlenecks and resolving them – often using some ideas from the previous sections.